

En el verano de 2017, un grupo de investigadores de Google Brain publicó un artículo que cambiaría para siempre el rumbo de la inteligencia artificial. Titulado «Attention Is All You Need«, este documento académico no llegó con grandes anuncios ni portadas, sino que debutó en la conferencia Neural Information Processing Systems (NeurIPS), un evento técnico donde las ideas innovadoras suelen tardar años en alcanzar el reconocimiento general. Aunque pocos fuera de la comunidad de investigación en IA lo sabían en ese momento, este artículo sentaría las bases para casi todos los modelos de IA generativa importantes que conocemos hoy, desde el GPT de OpenAI hasta las variantes LLaMA de Meta, BERT, Claude y Bard.
El Transformer es una arquitectura de red neuronal innovadora que elimina las antiguas suposiciones sobre el procesamiento de secuencias. En lugar de un procesamiento lineal y paso a paso, el Transformer adopta un mecanismo paralelizable, anclado en una técnica conocida como autoatención. En cuestión de meses, el Transformer revolucionó la forma en que las máquinas entienden el lenguaje. Antes del Transformer, el procesamiento del lenguaje natural (NLP) de vanguardia dependía en gran medida de las redes neuronales recurrentes (RNNs) y sus refinamientos, como las LSTMs (Long Short-Term Memory networks) y las GRUs (Gated Recurrent Units).
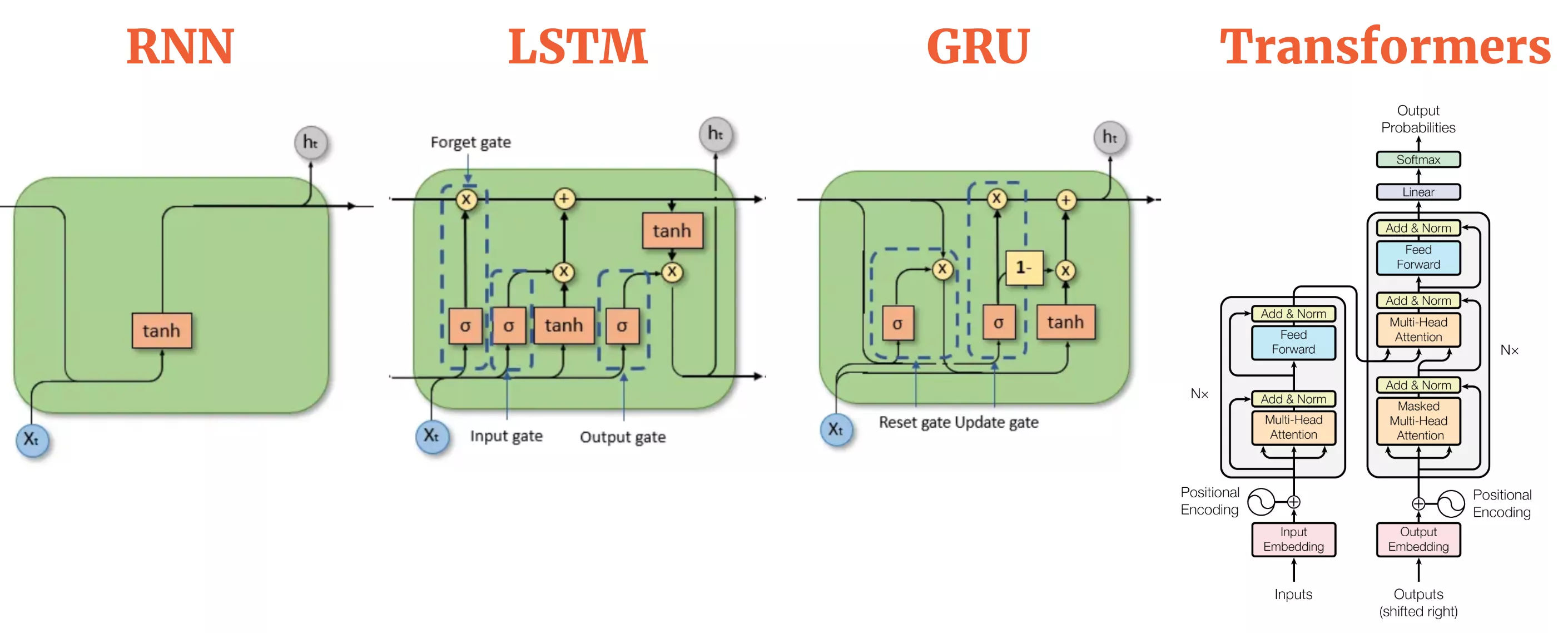
Estas redes neuronales recurrentes procesaban el texto palabra por palabra, pasando un estado oculto destinado a codificar todo lo leído hasta ese momento. Sin embargo, estas arquitecturas más antiguas presentaban importantes limitaciones. Por un lado, tenían dificultades con oraciones muy largas, y la paralelización era complicada porque cada paso dependía del anterior. El campo necesitaba desesperadamente una forma de procesar secuencias sin quedar atrapado en un enfoque lineal.
Los investigadores de Google Brain se propusieron cambiar esa dinámica. Su solución fue sorprendentemente simple: eliminar la recurrencia por completo. En su lugar, diseñaron un modelo que podía examinar cada palabra de una oración simultáneamente y determinar cómo se relacionaba cada palabra con las demás. Este ingenioso truco, denominado «mecanismo de atención», permitió al modelo centrarse en las partes más relevantes de una oración sin la carga computacional de la recurrencia. El resultado fue el Transformer: rápido, paralelizable y sorprendentemente eficaz en el manejo del contexto en largos tramos de texto.
La idea revolucionaria fue que la «atención», y no la memoria secuencial, podría ser el verdadero motor para entender el lenguaje. Los mecanismos de atención ya existían en modelos anteriores, pero el Transformer elevó la atención de un papel secundario a la estrella del espectáculo. Sin el marco de atención completa del Transformer, la IA generativa tal como la conocemos probablemente seguiría atrapada en paradigmas más lentos y limitados.
El Transformer no solo es eficaz en el texto. Los investigadores descubrieron que los mecanismos de atención podían funcionar en diferentes tipos de datos: imágenes, música, código. Pronto, modelos como CLIP y DALL-E comenzaron a combinar la comprensión textual y visual, generando arte «único» o etiquetando imágenes con una precisión asombrosa. La comprensión de vídeos, el reconocimiento de voz e incluso el análisis de datos científicos comenzaron a beneficiarse de este mismo esquema subyacente. Además, marcos de software como TensorFlow y PyTorch incorporaron bloques de construcción compatibles con Transformers, facilitando la experimentación para aficionados, startups y laboratorios industriales.
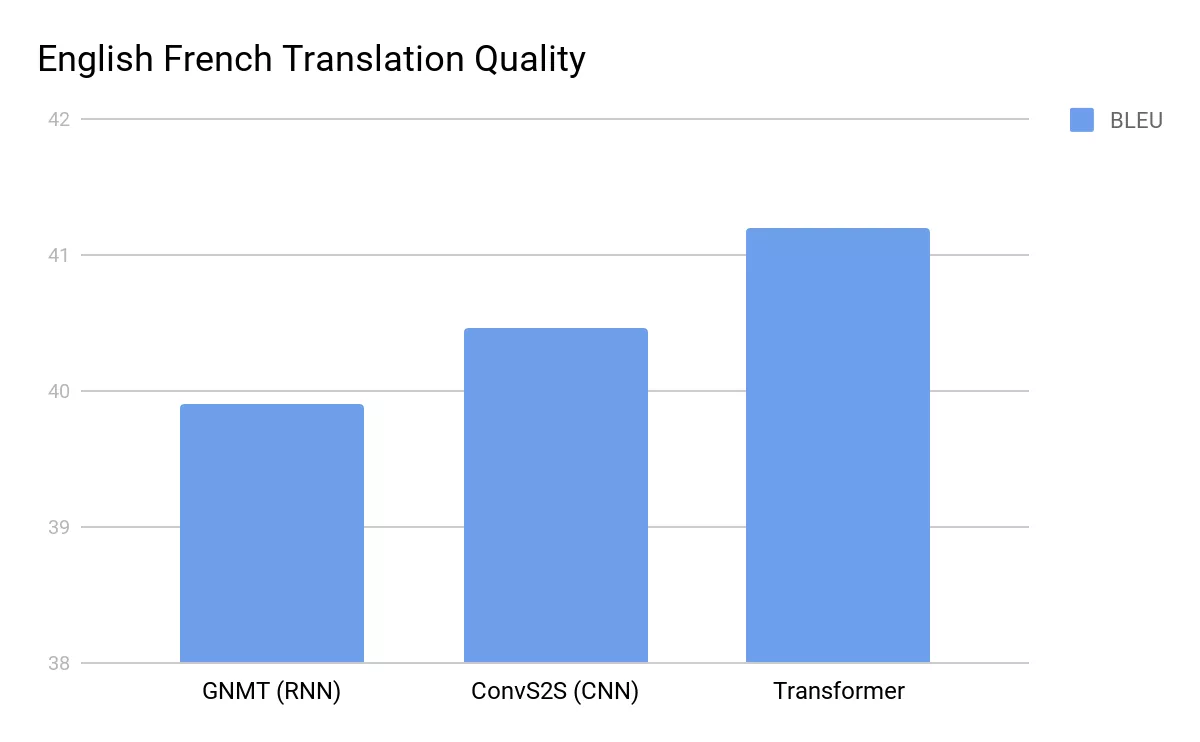
Un descubrimiento clave que surgió a medida que los investigadores continuaban explorando los Transformers fue el concepto de leyes de escalado. Experimentos realizados por OpenAI y DeepMind encontraron que, al aumentar el número de parámetros en un Transformer y el tamaño de su conjunto de datos de entrenamiento, el rendimiento mejora de manera predecible. Esta linealidad se convirtió en una invitación a una especie de carrera armamentista: modelos más grandes, más datos, más GPUs. Google, OpenAI, Microsoft y muchos otros han invertido enormes recursos en la construcción de modelos colosales basados en Transformers.
Sin embargo, todos los avances tecnológicos vienen con efectos secundarios, y la influencia del Transformer en la IA generativa no es una excepción. Incluso en esta etapa temprana, los modelos de IA generativa han inaugurado una nueva era de medios sintéticos, planteando preguntas complejas sobre derechos de autor, desinformación, suplantación de figuras públicas y el despliegue ético. Los mismos modelos de Transformer que pueden generar prosa convincentemente humana también pueden producir desinformación y resultados tóxicos. Los sesgos pueden estar presentes en los datos de entrenamiento, lo que puede ser sutilmente integrado y amplificado en las respuestas ofrecidas por los modelos de IA generativa.
El artículo «Attention Is All You Need» sigue siendo un testimonio de cómo la investigación abierta puede impulsar la innovación global. Al publicar todos los detalles clave, el documento permitió que cualquiera, competidor o colaborador, construyera sobre sus ideas. Ese espíritu de apertura por parte del equipo de Google ha alimentado la asombrosa velocidad a la que la arquitectura Transformer se ha extendido por la industria. Solo estamos comenzando a ver lo que sucede a medida que estos modelos se vuelven más especializados, más eficientes y más accesibles. La comunidad de aprendizaje automático necesitaba urgentemente un modelo que pudiera manejar la complejidad a gran escala, y hasta ahora, la autoatención ha cumplido con creces.











, un evento técnico donde las ideas innovadoras suelen tardar años en alcanzar el reconocimiento general.){kind=link}