
Imagina conducir por un túnel en un vehículo autónomo y, sin saberlo, un accidente ha detenido el tráfico más adelante. Normalmente, necesitarías confiar en el coche de delante para saber cuándo frenar. Pero, ¿y si tu vehículo pudiera ver más allá del coche de enfrente y aplicar los frenos incluso antes?
Investigadores del MIT y Meta han desarrollado una técnica de visión por computador que podría hacer esto posible en el futuro. Han introducido un método llamado PlatoNeRF, que crea modelos 3D precisos de una escena completa, incluyendo áreas bloqueadas, usando imágenes de una sola posición de cámara. Su técnica utiliza sombras para determinar qué hay en las partes ocultas de la escena.
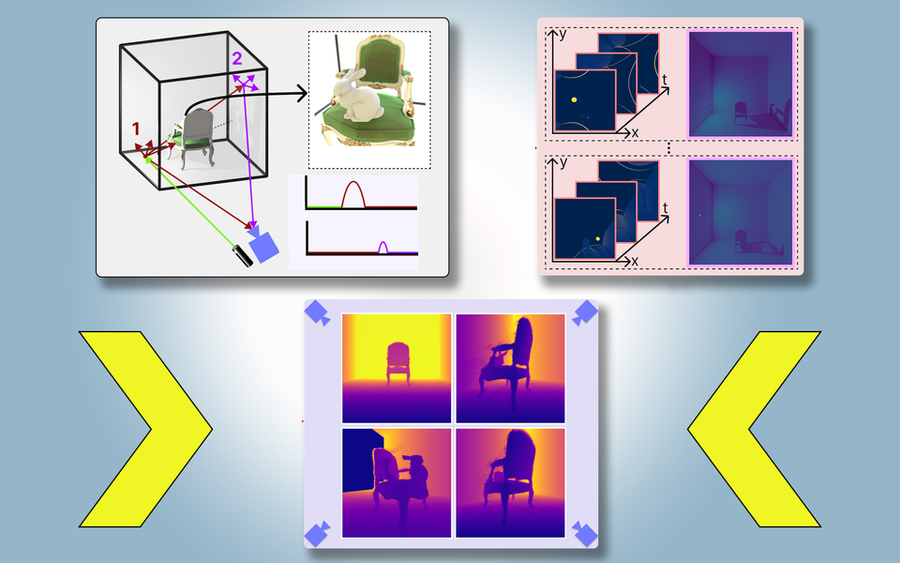
El nombre PlatoNeRF está inspirado en la alegoría de la caverna de Platón, donde prisioneros en una cueva perciben la realidad exterior a través de sombras en la pared. Combinando tecnología lidar (detección y rango de luz) con aprendizaje automático, PlatoNeRF puede generar reconstrucciones más precisas de la geometría 3D que algunas técnicas de IA existentes. Además, es mejor para reconstruir suavemente escenas donde las sombras son difíciles de ver, como en ambientes con mucha luz ambiental o fondos oscuros.
Además de mejorar la seguridad de los vehículos autónomos, PlatoNeRF podría hacer más eficientes los auriculares de realidad aumentada/virtual (AR/VR) permitiendo al usuario modelar la geometría de una habitación sin necesidad de caminar y tomar medidas. También podría ayudar a los robots de almacén a encontrar artículos en entornos desordenados más rápidamente.
Reconstruir una escena 3D completa desde un solo punto de vista de cámara es un problema complejo. Algunas aproximaciones utilizan modelos de IA generativa que intentan adivinar qué hay en las regiones ocultas, pero estos modelos pueden alucinar objetos que no están realmente allí. Otros métodos intentan inferir las formas de los objetos ocultos usando sombras en una imagen de color, pero pueden tener dificultades cuando las sombras son difíciles de ver.
Para PlatoNeRF, los investigadores del MIT se basaron en estos enfoques utilizando una nueva modalidad de detección llamada lidar de un solo fotón. Los lidars mapean una escena 3D emitiendo pulsos de luz y midiendo el tiempo que tarda esa luz en rebotar de nuevo al sensor. Debido a que los lidars de un solo fotón pueden detectar fotones individuales, proporcionan datos de mayor resolución.
El sistema ilumina secuencialmente 16 puntos, capturando múltiples imágenes que se utilizan para reconstruir toda la escena 3D. La clave de PlatoNeRF es la combinación de lidar de múltiples rebotes con un modelo de aprendizaje automático conocido como campo de radiancia neural (NeRF). Un NeRF codifica la geometría de una escena en los pesos de una red neuronal, lo que da al modelo una fuerte capacidad para interpolar o estimar nuevas vistas de una escena.
Los investigadores compararon PlatoNeRF con dos métodos alternativos comunes, uno que solo usa lidar y otro que solo usa NeRF con una imagen en color. Descubrieron que su método superaba a ambas técnicas, especialmente cuando el sensor lidar tenía una resolución más baja, lo que haría su enfoque más práctico para desplegar en el mundo real, donde los sensores de menor resolución son comunes en los dispositivos comerciales.
En el futuro, los investigadores quieren intentar rastrear más de dos rebotes de luz para ver cómo eso podría mejorar las reconstrucciones de la escena. Además, están interesados en aplicar más técnicas de aprendizaje profundo y combinar PlatoNeRF con mediciones de imágenes en color para capturar información de textura.










