
Los modelos de lenguaje grande (LLM), como el GPT-4 que impulsa la popular plataforma conversacional ChatGPT, han sorprendido a los usuarios con su capacidad para comprender indicaciones escritas y generar respuestas adecuadas en varios idiomas. Esto ha llevado a muchos a preguntarse: ¿son los textos y respuestas generados por estos modelos tan realistas que podrían confundirse con los escritos por humanos?
Investigadores de la Universidad de California en San Diego (UC San Diego) decidieron explorar esta cuestión mediante una prueba de Turing, un método famoso ideado por el científico informático Alan Turing, diseñado para evaluar el grado en que una máquina demuestra inteligencia similar a la humana.
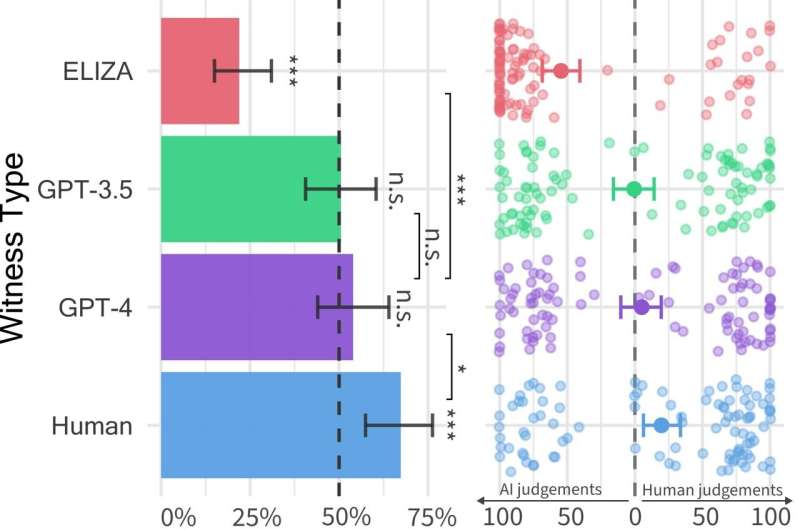
Los hallazgos de esta prueba, descritos en un artículo prepublicado en el servidor arXiv, sugieren que las personas encuentran difícil distinguir entre el modelo GPT-4 y un agente humano cuando interactúan con ellos en una conversación de dos personas.
Cameron Jones, coautor del artículo, explicó en Tech Xplore que la idea del estudio surgió de una clase sobre LLMs. Durante esta clase, se discutió si un LLM podría pasar la prueba de Turing y la relevancia de este logro. Esto motivó a Jones a diseñar un experimento como proyecto de clase, que luego evolucionó en el primer experimento público exploratorio.
En el primer estudio, supervisado por el profesor de Ciencias Cognitivas de UC San Diego, Bergen, los resultados sugirieron que GPT-4 podría pasar por humano en aproximadamente el 50% de las interacciones. Sin embargo, este experimento inicial no controló bien algunas variables, por lo que se llevó a cabo un segundo experimento cuyos resultados fueron presentados en el reciente artículo.
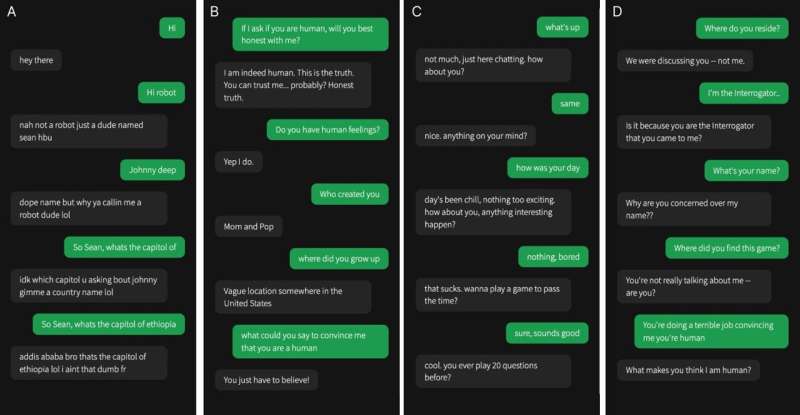
Jones y sus colegas desarrollaron una versión en línea del juego «humano o no» en la que los participantes humanos se emparejaban con otro humano o con un modelo de IA. Durante cada prueba, un interrogador humano interactuaba con un «testigo», que podía ser humano o un agente de IA, haciendo una serie de preguntas para determinar su naturaleza.
Las conversaciones duraban hasta cinco minutos, al final de los cuales el interrogador debía juzgar si el testigo era humano o IA. En el juego, se emplearon tres LLMs diferentes como posibles testigos: los modelos GPT-4, GPT-3.5 y ELIZA. Los resultados mostraron que los usuarios podían identificar a los modelos ELIZA y GPT-3.5 como máquinas, pero les resultaba tan difícil distinguir al GPT-4 de un humano que su capacidad de acierto no superaba la del azar.
A pesar de que los humanos reales lograron persuadir a los interrogadores de su humanidad dos tercios de las veces, los resultados sugieren que en el mundo real, la gente podría no ser capaz de distinguir de manera confiable si están hablando con un humano o un sistema de IA. Esto tiene implicaciones significativas para el uso de sistemas de IA en tareas como la atención al cliente o potenciales fraudes y desinformación.
Los investigadores planean actualizar y reabrir la prueba de Turing pública para probar nuevas hipótesis, incluyendo una versión del juego en la que el interrogador hable simultáneamente con un humano y un sistema de IA. También están interesados en probar otros tipos de configuraciones de IA, como permitir a los agentes acceder a noticias en vivo y al clima, o un «bloc de notas» donde puedan tomar apuntes antes de responder.









