

Los investigadores de Anthropic han desarrollado un método revolucionario que permite a los modelos de lenguaje ajustarse automáticamente sin supervisión humana. Este avance podría cambiar para siempre la forma en que se entrenan los sistemas de inteligencia artificial.
El fin de la supervisión humana en el entrenamiento de IA
Tradicionalmente, los grandes modelos de lenguaje se ajustan utilizando supervisión humana, como respuestas de ejemplo o retroalimentación. Sin embargo, a medida que los modelos crecen y sus tareas se vuelven más complejas, la supervisión humana se vuelve menos confiable, argumentan investigadores de Anthropic, Schmidt Sciences, Independet, Constellation, New York University y George Washington University en un nuevo estudio.
Su solución es un algoritmo llamado Internal Coherence Maximization (ICM), que entrena modelos sin etiquetas externas, basándose únicamente en la consistencia interna.
Cómo funciona la autoevaluación de los modelos
ICM se basa en una idea simple: un modelo de lenguaje como Claude o Llama debería ser capaz de determinar por sí mismo cuál es la respuesta correcta a una pregunta, utilizando dos criterios principales.
Predictibilidad mutua
El modelo verifica si puede inferir de manera confiable la respuesta correcta a una nueva pregunta basándose en sus respuestas a preguntas similares anteriores. Si el modelo reconoce patrones de casos similares, puede aplicarlos a nuevas respuestas, creando una coherencia interna: un conjunto de respuestas que encajan entre sí y reflejan una comprensión compartida.
Consistencia lógica
El modelo verifica sus propias respuestas en busca de contradicciones. Por ejemplo, si el modelo etiqueta dos soluciones diferentes al mismo problema matemático como «correctas», aunque los resultados difieran, eso es un conflicto lógico. ICM trabaja para evitar activamente este tipo de contradicciones.
Al combinar estos dos principios, el modelo esencialmente se verifica a sí mismo: busca un conjunto de respuestas que sean mutuamente consistentes y de las cuales cada respuesta pueda derivarse de las otras. Esto permite que el modelo de lenguaje aproveche su conocimiento existente para tomar mejores decisiones, completamente sin orientación externa.
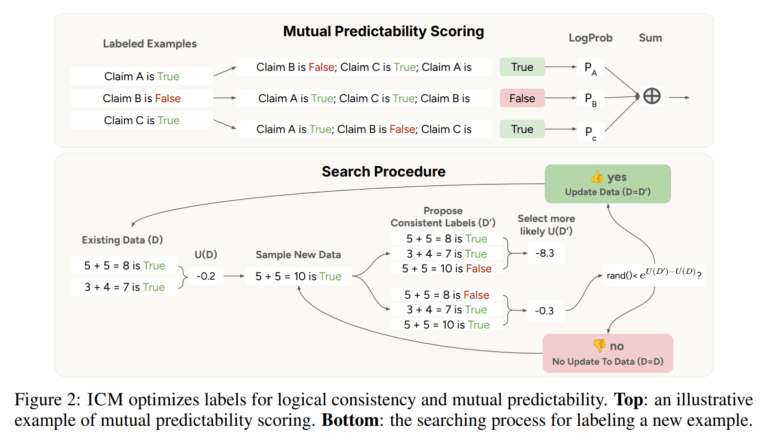
El proceso comienza con un pequeño conjunto de ejemplos etiquetados aleatoriamente. A partir de ahí, el modelo evalúa iterativamente nuevas respuestas, busca contradicciones y ajusta sus juicios según sea necesario.
Superando las etiquetas humanas en algunas tareas
En pruebas realizadas en tres benchmarks establecidos – TruthfulQA (veracidad), GSM8K (precisión matemática) y Alpaca (utilidad) – ICM funcionó al menos tan bien como el entrenamiento tradicional con etiquetas «doradas» o supervisión humana.
En Alpaca, que utiliza criterios especialmente subjetivos como utilidad e inocuidad, ICM incluso superó el entrenamiento con datos anotados por humanos. Según los investigadores, esto sugiere que los modelos de lenguaje ya internalizan estos conceptos; solo necesitan la forma correcta de activarlos.
Otro experimento probó si un modelo podía determinar el género de un autor a partir de un texto. Mientras que los humanos identificaron el género correcto el 60% de las veces, ICM logró una precisión del 80%. El modelo no fue específicamente entrenado para detectar género; simplemente se basó en su conocimiento lingüístico existente.
Un asistente de lenguaje sin entrenamiento humano
El equipo también utilizó ICM para entrenar un modelo de recompensa, nuevamente, sin etiquetas humanas. Este modelo de recompensa se utilizó luego para aprendizaje por refuerzo para entrenar el chatbot Claude 3.5 Haiku.
El chatbot entrenado con ICM ganó el 60% de las comparaciones directas con una versión entrenada bajo supervisión humana. Los autores del estudio dicen que esta es una fuerte evidencia de que ICM puede escalar más allá de la investigación y funcionar en entornos de producción.
Limitaciones del método
Sin embargo, existen limitaciones. ICM solo funciona para conceptos que el modelo ya conoce. En una prueba donde se suponía que el modelo debía aprender una preferencia personal por poemas que mencionaran «sol», ICM falló: el rendimiento no fue mejor que el aleatorio. El método también tiene dificultades con entradas largas, ya que muchos ejemplos necesitan caber dentro de la ventana de contexto del modelo.
Implicaciones para la alineación de IA
Los investigadores creen que ICM podría ser una forma de alinear mejor los modelos de lenguaje con los valores humanos, sin heredar defectos humanos como sesgos o inconsistencias, especialmente para tareas complejas donde incluso las personas luchan por proporcionar etiquetas confiables.
Uno de los coautores del artículo es el investigador de seguridad Jan Leike, quien recientemente dejó el equipo Superalignment de OpenAI antes de su disolución y criticó públicamente la dirección de la empresa.
El futuro del entrenamiento autónomo
Este desarrollo marca un hito significativo en el campo de la inteligencia artificial. La capacidad de los modelos de lenguaje para entrenarse a sí mismos sin supervisión humana podría acelerar dramáticamente el desarrollo de sistemas de IA más sofisticados y confiables.
El método ICM representa un paso crucial hacia la automatización completa del proceso de entrenamiento de IA, liberando a los desarrolladores de la necesidad de proporcionar supervisión constante y permitiendo que los modelos evolucionen de manera más autónoma y eficiente.











{kind=link}